|
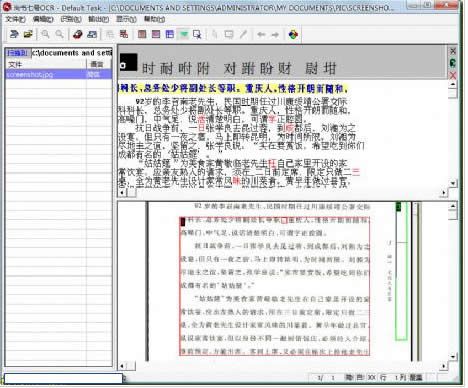
软件是一系列按照特定顺序组织的计算机数据和指令的集合。一般来讲软件被划分为编程语言、系统软件、应用软件和介于这两者之间的中间件。硬件是“计算机硬件”的简称。与“软件”相对,电子计算机系统中所有实体部件和设备的统称。 尚书七号是很多办公室工作人员日常生活中会用到的软件,不过对于新手来说尚书七号的操作方式并不那么熟练。用扫描仪扫描的文字图像,不能对个别文字进行编辑修改,在教学中,需要利用文字识别软件,将文字图像进行识别,将图像格式转化成文本格式,常见的文字识别软件有很多,主要功能基本相同,在此以ScanMaker 4850ii随机附送的尚书七号为例,介绍用文字识别软件对扫描仪扫描的文字图像进行识别的正确使用方法。 用尚书七号对文字图像识别转化的过程,利用其主菜单:“文件”、“编辑”、“识别”、“输出”可以很方便地完成。
具体步骤为: 步骤1:获取文字图像文件。 选择“文件”菜单下的“扫描”或“打开图像”(将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择“文件”菜单下的“选择扫描仪”命令,调用扫描仪。 步骤2:对扫描的图像页进行调整 选择“编辑”菜单下“图像页面的处理”子菜单下的“图像页的倾斜校正”(提供自动和手动实现方法)及“旋转”等命令,将扫描的图像页进行调整。 步骤3:版面分析与文字识别转化 版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是“版面分析”。尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。 设置好后,直接点击“开始识别”的按钮就可以进行文字识别了。 步骤4:校对修改 自动识别完毕,识别结果的“文本窗口”会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。 提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。 步骤5:输出 如果检查修改后确认无误,选择识别结果的“输出”菜单,输出的文件格式有:RTF、HTML、XLS、TXT,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。 其实任何软件都没有困难之说,只要大家掌握了方法就能熟练使用,其实尚书七号是很简单的,大家只要根据上述的五个步骤就能完成。 硬件是实在的,有模有样的。软件是程序性的。是一系列的指令。有了软件,硬件才会实现更丰富的功能。 |
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和GHOST系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(kfyvi376850063@126.com),我们会及时处理.
Copyright © 2018-2022 系统之家 关于本站